Introducing Amazon Web Services (AWS)

Hello everyone, my name is Victor Leung and I am an AWS community builder. In this article, I would like to introduce Amazon Web Service (AWS). You may be wondering, what is AWS? It is the world's most comprehensive and well-adopted cloud platform. Customers trust AWS to power their infrastructure and applications. Organisations of every type and size are using AWS to lower costs, become more agile and innovate faster.
AWS provides on-demand delivery of technology services via the internet with pay-as-you-go pricing. You can use these services to run any type of application without upfront costs or ongoing commitments. You only pay for what you use.
Moreover, AWS gives you more services and more features within those services than any other cloud provider. This makes it faster, easier and more cost-effective to move your existing application to the cloud and to build anything you can imagine.
You can rely on AWS's globally deployed infrastructure to scale your application to meet growing demand. There are so many regions in the world, how to choose? You can start with the region closest to you and your customer. A region is a physical location in the world that consists of multiple Availability Zones. Each availability zones consist of one or more discrete data centres, each with redundant power, networking, and connectivity, housed in separate facilities. In the future, if your company expands to other regions, you can take advantage of AWS facilities as well. The AWS Cloud spans 84 Availability Zones within 26 geographic regions around the world, with announced plans for 24 more Availability Zones and 8 more AWS Regions.
As for the computing power on the cloud platform, there are several types to choose from. You can use the EC2 virtual server service to deploy your server on the platform. And there are so many types of EC2, how to choose? In fact, it is decided according to your needs, the four aspects are the CPU, memory, storage and network performance. According to the type, age, capability and size, there are certain naming conventions, such as M5d.xlarge.
Generally speaking, for the instance selection process, you can start with the best-guess instance. Then determine the constrained resources. For example, C5 instances are optimised for compute-intensive workloads. It is suited for high-performance web servers. It has cost-effective high performance at a low price per compute the ratio. Besides, for M5 instances, they are general purpose instances. It has a balance of compute, memory, and network resources. It is a good choice for many applications.
Once you started an EC2 instance, you may change the instance type as well. You can resize for over-utilized (the instance type is too small) or under-utilized (the instance type is too large) cases. This only works for EBS-backed instances. The steps are 1. Stop instance 2. Instance Settings -> Change Type 3. Start Instance. You cannot change the instance type of a Spot Instance and you cannot change the instance type if hibernation is enabled.
There are a couple of available CloudWatch metrics for your EC2 instances:
- CPUUtilization: the percentage of allocated EC2 compute units
- DiskReadOps: completed read operations from all instance store volumes
- DiskWriteOps: completed write operations to all instance store volumes
- DiskReadBytes: bytes read from all instance store volumes
- DiskWriteBytes: bytes written to all instance store volumes
- MetadataNoToken: number of times the instance metadata service was successfully accessed using a method
- NetworkIn: number of bytes received by the instance
- NetworkOut: number of bytes sent out by the instance
- NetworkPacketsIn: number of packets received by the instance
- NetworkPacketsOut: number of packets sent out by the instance
Besides, you can install the CloudWatch agent to collect memory metrics and log files.
When purchasing EC2, there are many options. You can start with an on-demand instance first, billed by the second, with no long-term contract. After you try it out in the future, you can choose a more cost-effective reserved instance and pay for a long-term lease of one to three years, which will save you money in the long run.
After choosing the purchase method, you can put the EC2 virtual machine into the auto-scaling group. When the demand increases, the number of EC2s can be increased at the same time, thereby increasing the computing power. When the peak period is over, such as when there is no traffic in the early morning, the number of EC2s can be automatically reduced. This automatic scaling function can be scaled independently according to different indicators, and this function is free to use.
For EC2 Load Balancing, by default, the round robin routing algorithm is used to route requests at the target group level. It is a good choice when the requests and targets are similar, or if you need to distribute requests equally among targets. You can specify the least outstanding requests routing algorithm, with consideration for capacity or utilization, to prevent over-utilization or under-utilization of targets in target groups when requests had varied processing times or targets were frequently added or removed. If you enable sticky sessions, the routing algorithm of the target group is overridden after the initial target selection.
Elastic Load Balancer (ELB) can be used to automatically assigned to one or more availability zones, and at the same time, it can check the health status of the backend servers, and increase or decrease resources horizontally according to traffic requirements. There are also several different options for load balancers. For Application Loan Balancer (ALB), which is configured according to the OSI layer 7, which is HTTP. Other load balancer can also be distributed through the fourth layer of the network OSI, using the protocols of TCP and UDP, as well as the distributor of the gateway.
Suppose your business is unlucky to encounter a large-scale accident, such as a natural disaster, an earthquake, damage to a data centre, a technical impediment, or a human error, such as an employee running a command rm -rf deletes all the data, so what should you do? Actually, there are different methods, and there are also different restoration times and origins.

As for the different methods, different costs would be charged. The higher the cost, the faster the recovery. If your business can tolerate a few hours of service interruption, a normal backup and restore scenario is fine. But if it doesn't work, and it takes a few minutes to restore service, then it's a matter of replicating an identical environment in a different region, and in a standby state.
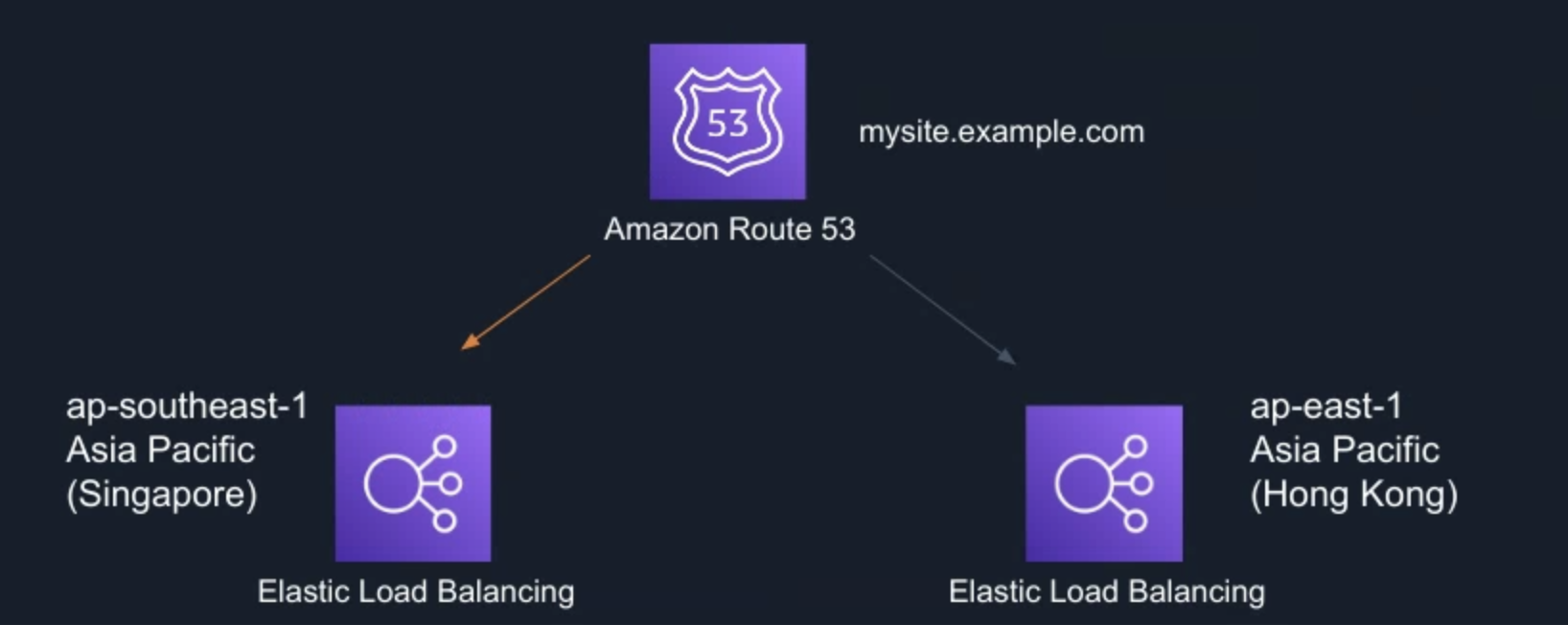
Let me give you an example, such as deploying a website to an environment in Singapore, and deploying a backup environment in Hong Kong at the same time. Through the Route53 domain name system, the domain name is pointed to the Singapore region. When a problem occurs in the Singapore area and the entire area cannot be used, the domain name can be transferred to the Hong Kong area immediately, and normal services can be resumed. The process can be changed manually or automatically, or even distributed proportionally or on a user-by-user basis.
However, operating in two regions is relatively expensive. For generally small-scale problems, such as component failures, network issues, or sudden increases in traffic, deploying to two or more Availability Zones is fine. When a zone is unavailable, it is immediately moved to another available zone, and data can be independently replicated.
Regarding to database, you can choose RDS, which is compatible with MySQL database and can be resized. RDS is a hosted service that handles patching, backup and restore functions for you. In the future, you can also consider using Aurora. The throughput can reach about three times, but the price is also more expensive, depending on whether you want to achieve the performance of a business database.
RDS allows multi-AZ deployments, which provides enterprise-grade high availability, fault tolerance across multiple data centres with automatic failover, and synchronous replication and enabled with one click. When failing over, Amazon RDS simply flips the canonical name record (CNAME) for your DB instance to point at the standby, which is in turn promoted to become the new primary.

The RDS read replicas provide read scaling and disaster recovery. It relieve pressure on your master node with additional read capacity. It bring data close to your application in different regions You can promote a read replica to a master for faster recovery in the event of disaster.
If you need strict read-after-write consistency (what you read is what you just wrote) then you should read from the main DB Instance. Otherwise, you should spread out the load and read from one of the read replicas. The read replicas track all of the changes made to the source DB Instance. This is an asynchronous operation. Read Replicas can sometimes be out of date with respect to the source. This phenomenon is called replication lag. Replica Lag metric in Amazon CloudWatch to allow you to see how far it has fallen behind the source DB Instance.
Amazon RDS encrypted DB instances use the industry standard AES-256 encryption algorithm to encrypt your data on the server that hosts your Amazon RDS DB instances. To protect data in transit, all AWS service endpoints support TLS to create a secure HTTPS connection to make API requests. Manage secrets, API keys, and credentials with AWS Key Management Service (AWS KMS). As the team expands, with AWS Identity and Access Management (IAM), you can specify who or what can access services and resources in AWS, centrally manage fine-grained permissions, and analyze access to refine permissions across AWS. Multi-factor authentication (MFA) in AWS is a simple best practice that adds an extra layer of protection on top of your user name and password. Firewalls (web application, network) and DDoS protection. Thread detection, manage secret alerts, and configure security controls for individual AWS services using AWS Security, Identity & Compliance.
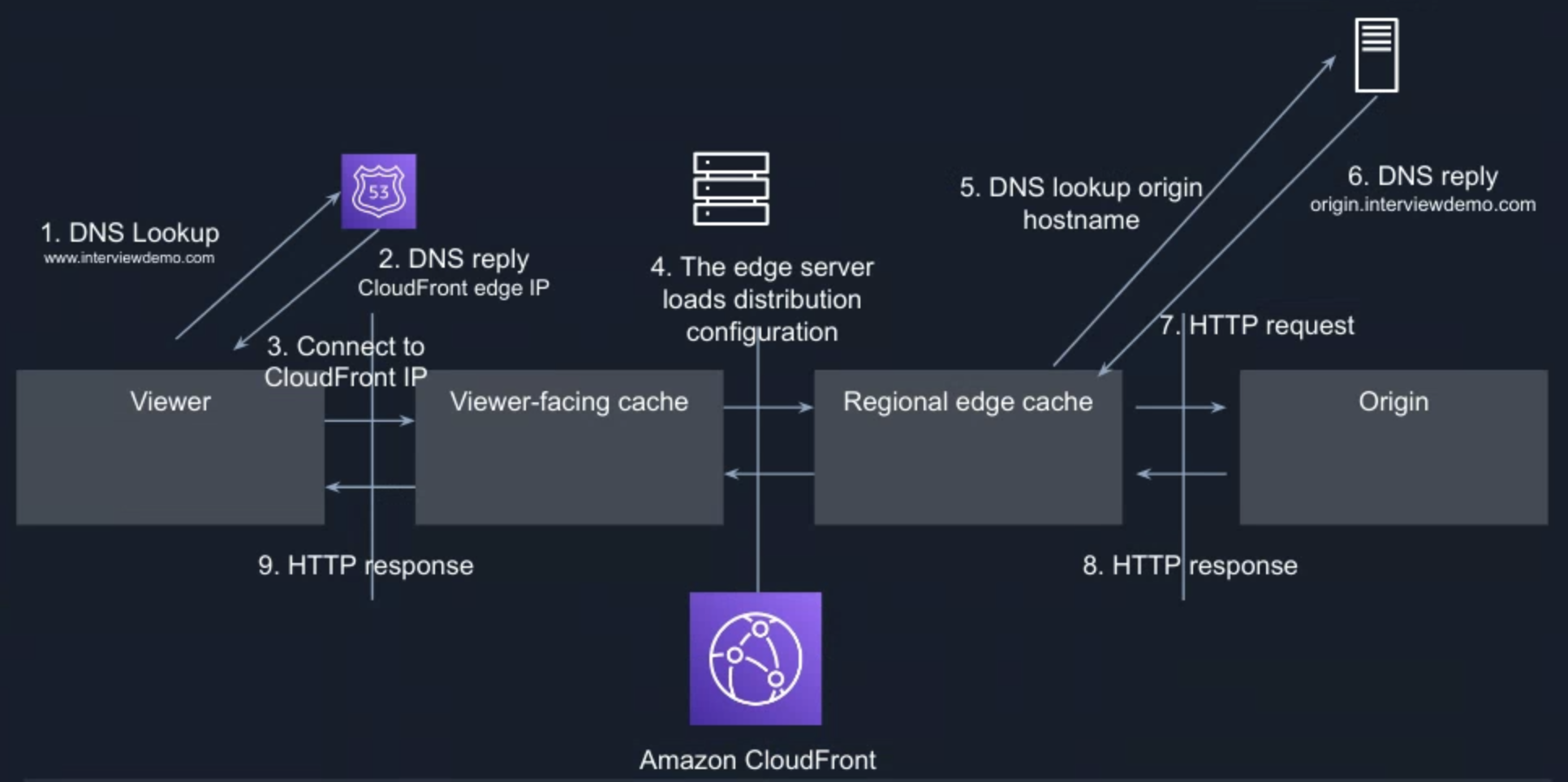
Amazon CloudFront is a content delivery network (CDN) service built for high performance, security, and developer convenience. It speeds up the distribution of your web content to your users, through a worldwide network of data centres called edge locations. The user request is routed to the edge location that provides the lowest latency (time delay), so that content is delivered with the best possible performance. For example, the first client sends a request in the United States, and then needs to cross half the world to Singapore to get the content, but for the second request, it is good to get the previous cache file in the data centre near the United States, which greatly reduces the distance and feedback time.

For dynamic content acceleration, you can use standard cache control headers you set on your files to identify static and dynamic content. Dynamic content is not cacheable, it proxied by CDN to the origin and back. Faster response time = Reduced DNS Time (Route 53) + Reduced Connection Time (Keep-Alive Connections & SSL Termination)+ Reduced First Byte Time (Keep-Alive Connections)+ Reduced Content Download Time (TCP/IP Optimization). It can further optimise using Latency-based Routing (LBR), run multiple stacks of the application in different Amazon EC2 regions around the world, create LBR records for each location and tag the location with geo information. Route 53 will route end users to the endpoint that provides the lowest latency.

AWS CodePipeline is a fully managed continuous delivery service that helps you automate your release pipelines for fast and reliable applications. It can use to prevent issues by running tests and performing ng quality check. Amazon CloudWatch is a monitoring and observability service. It provides you with data and actionable insights to monitor your applications, respond to system-wide performance changes, and optimize resource utilization. Upon detection of abnormal patterns or healthh check returns error, you can trigger an alarm or actions, which could further trigger AWS Lambda, it is serverless, event-driven compute service that lets you mitigate the issue, such as restart the server or revert to the previous stable version. You can then recover from failed service instances.
For storage of objects, there are 6 choices of Amazon Simple Storage Services (Amazon S3) storage classes: S3 standard, S3 standard-IA, S3 One Zone-IA, S3 intelligent-tiering, S3 Glacier, S3 Glacier Deep Archive. The Amazon S3 Glacier storage classes are purpose-built for data archiving, providing you with the highest performance, most retrieval flexibility, and the lowest cost archive storage in the cloud.
For S3 Data Consistency, the New Objects (PUTS) has Read After Write Consistency. When you upload a new S3 object you are able to read it immediately after writing. Overwrite (PUTS) or Delete Objects got Eventual Consistency. When you overwrite or delete an object, it takes time for S3 to replicate versions to AZs. If you read it immediately, S3 may return you an old copy. You need to generally wait a few seconds before reading.
Another storage option is EBS. What is Amazon Elastic Block Storage (EBS)? Block storage volumes as a service attached to Amazon EC2 instances. It is flexible storage and performance for dynamic workloads such as stateful containers. It can be created, attached, and manage volumes through API, SDK, or AWS console. It has point-in-time snapshots and tools to automate backup and retention via policies.
gp3, General Purpose SSD are great for boot volumes, low-latency applications, and bursty databases.
- IOPS: 3,000 - 16,000 IOPS
- Throughput: 128 - 1,000 MiB/s
- Latency: Single-digit ms
- Capacity: 1 GiB to 16 TiB
- I/O Size: Up to 256 KiB (logical merge)
io2, Block Express are ideal for critical applications and databases with sustained IOPS. It’s next-generation architecture provides 4x throughput and 4x IOPS.
- Up to 4,000 MiB/s
- Up to 256,000 IOPS
- 1,000:1 IOPS to GB
- 4x volume size up to 64 TB per volume
- < 1-millisecond latency
st1, Throughput optimized are ideal for large-block, high-throughput sequential workloads.
- Baseline: 40 MiB/s per TiB, up to 500 MiB/s
- Burst: 250 MiB/s per TiB, up to 500 MiB/s
- Capacity: 125 GiB to 16 TiB
- I/O Size: Up to 1 MiB (logical merge)
sc1, Cold HDD are ideal for sequential throughput workloads, such as logging and backup.
- Baseline: 12 MiB/s per TiB, up to 192 MiB/s
- Burst: 80 MiB/s per TiB, up to 250 MiB/s
- Capacity: 125 GiB to 16 TiB
- I/O Size: Up to 1 MiB (logical merge)
For EBS availability, EBS volume data is replicated across multiple servers in an Availability Zone to prevent the loss of data from the failure of any single component. Protect against failures with 99.999% availability, including replication within Availablity Zone (AZs), and 99.999% durability with io2 Block Express volumes. EBS Snapshots are stored in S3, which stores data across three availability zones within a single region.
Besides, there is Amazon Elastic File System (Amazon EFS). It is serverless shared storage - no provisioning, scale capacity, connections and IOPS. It is elastic - pay only for the capacity used. Performance build-in scales with capacity. It has high durability and availability - designed for 11 9s of durability and 99.99% availability SLA.
AWS CloudFormation is a service that helps you model and set up your AWS resources so that you can spend less time managing those resources and more time focusing on your applications that run in AWS. Infrastructure as code (IaC). Consistent across accounts and regions. Dev/test environments on demand. An Amazon Machine Image (AMI) is a supported and maintained image provided by AWS that provides the information required to launch an instance.
Finally, to sum up, there are many AWS services to archive well architecture with operational excellence, security, performance efficiency, reliability and cost optimisation. There is so much to learn and let’s keep learning. Thank you very much for taking the time to read this article. Let me know if you got any questions, happy to connect