MapReduce - 簡化的大數據處理方法
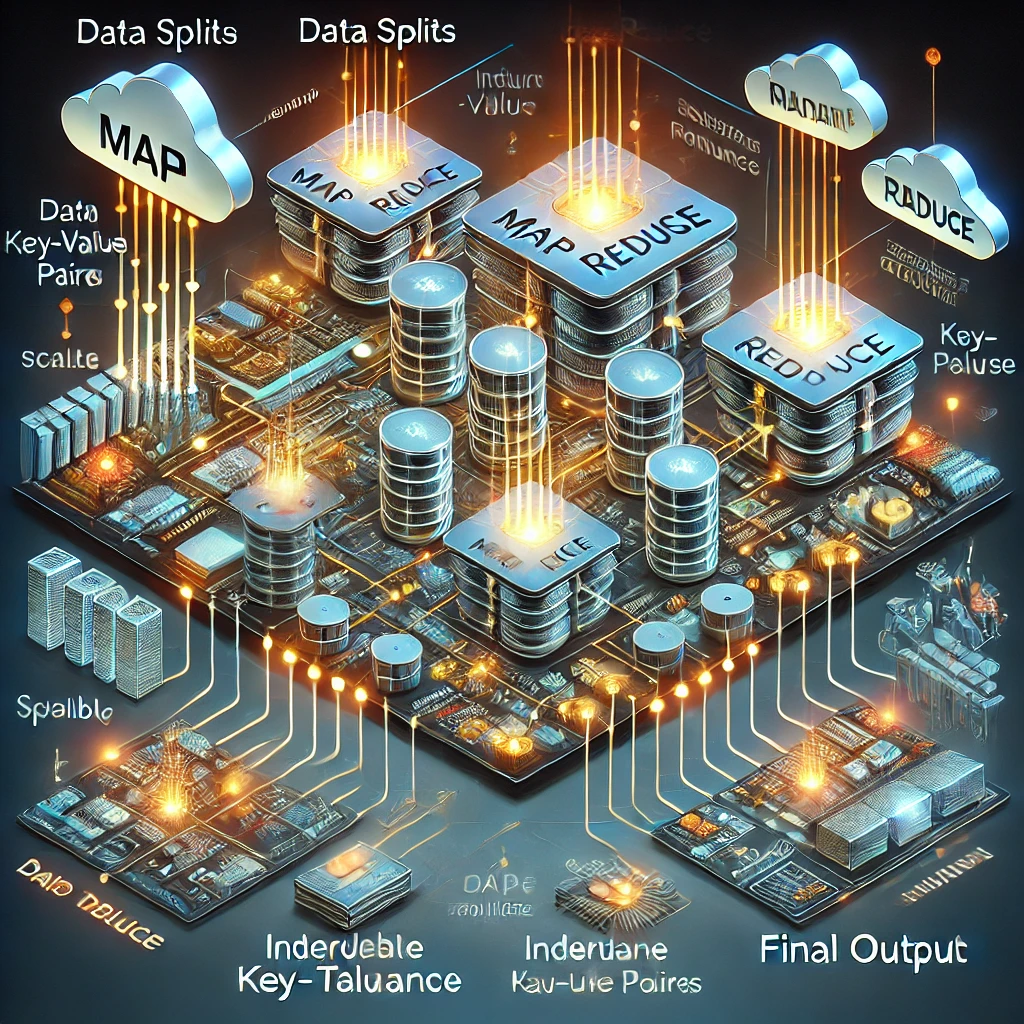
在大數據時代,跨分佈式系統處理和生成大規模數據集是一項挑戰。這正是 MapReduce 發揮作用的地方——這是一種簡化分佈式數據處理的編程模型。由 Jeffrey Dean 和 Sanjay Ghemawat 在 Google 開發的 MapReduce,透過抽象並簡化並行計算、數據分佈與容錯處理的複雜性,使數據處理變得可擴展且可靠。我們來探討這種變革性方法的運作方式,以及它為何如此重要。
什麼是 MapReduce?
MapReduce 包含兩個核心操作: 1. Map 函數:處理輸入的鍵/值對,產生中間鍵/值對。 2. Reduce 函數:將相同中間鍵的所有值彙總並輸出最終結果。
該模型的簡單性掩蓋了其強大能力。開發者僅需關注這兩個操作,即可為分佈式系統編寫高效程式,而無需擔心底層的任務調度、進程間通信或機器故障等問題。
MapReduce 的運作方式
MapReduce 作業的執行過程包含以下步驟: 1. 輸入分割(Input Splitting):數據被分割成小塊(通常為 16MB 到 64MB),以便並行處理。 2. Map 階段:每個數據塊由工作節點運行使用者定義的 Map 函數進行處理。 3. Shuffle 和 Sort:中間鍵/值對按鍵進行分組,準備進入 Reduce 階段。 4. Reduce 階段:分組後的數據由 Reduce 函數處理,生成最終結果。
MapReduce 框架處理複雜性,例如在發生故障時自動重新執行任務、優化數據本地性以減少網絡開銷,以及動態平衡負載。
實際應用
MapReduce 被廣泛應用於處理大規模數據的行業,包括: - 詞頻統計(Word Count):計算大型文檔語料庫中每個單詞的出現次數。 - 倒排索引(Inverted Index):構建文檔的可搜尋索引,對搜尋引擎至關重要。 - 網站日誌分析(Web Log Analysis):分析 URL 訪問頻率,或從伺服器日誌提取趨勢。 - 排序(Sorting):基於 TeraSort 基準的數據排序,處理數百 TB 數據。
這些應用案例展示了 MapReduce 在數據密集型與計算密集型任務中的高效處理能力。
MapReduce 的優勢
- 可擴展性:可在數千台機器上運行,無縫處理數 PB 級別數據。
- 容錯性:自動檢測並恢復機器故障,確保數據處理不中斷。
- 易用性:屏蔽分佈式系統的底層複雜性,使非專家也能利用並行計算。
- 靈活性:適用於各種領域,從索引構建到機器學習等應用場景。
- 高效資源利用:透過數據本地性優化,減少網絡帶寬消耗,提高運行效率。
挑戰與局限性
儘管 MapReduce 強大,但它也有一些局限性: - 批量處理:適用於批量數據處理,而非實時處理應用場景。 - I/O 瓶頸:中間結果存儲於磁盤,對某些工作負載可能導致效率降低。 - 表達能力受限:其簡單性不適用於所有演算法,特別是像圖計算這類需要多次迭代的應用。
影響與遺產
MapReduce 徹底改變了大數據處理模式,啟發了現代框架如 Apache Hadoop 和 Apache Spark 的誕生。其影響不僅限於具體應用,還塑造了分佈式系統的設計理念。
結論
MapReduce 透過抽象分佈式計算的複雜性,簡化了大規模數據處理。其簡單性、可擴展性和容錯機制,使其成為大數據生態系統的基石。無論是分析伺服器日誌,還是構建倒排索引,MapReduce 都提供了一個強大且可靠的框架,助力應對大數據時代的挑戰。